وبلاگ

نویسندگان: جوراج ولادیکا، مهدی داهینی، فلوریان متیس
دانشگاه فنی مونیخ، آلمان
دانشکدهی محاسبات، اطلاعات و فناوری
دپارتمان علوم کامپیوتر
حقایق به سرعت محو میشوند: ارزیابی حفظ دانش پزشکی منسوخ در مدلهای زبانی بزرگ(LLMs) 2025
چکیده: قابلیتهای رو به رشد مدلهای زبانی بزرگ (LLM) پتانسیل قابل توجهی را برای ارتقای مراقبتهای بهداشتی با کمک به محقق های پزشکی و پزشکان نشان میدهد. با این حال، اتکای آنها به دادههای آموزشی ایستا، زمانی که توصیههای پزشکی با تحقیقات و پیشرفتهای جدید تکامل مییابند، یک خطر بزرگ است. وقتی LLMها دانش پزشکی منسوخ را حفظ مینمایند، میتوانند توصیههای مضر ارائه دهند یا در وظایف استدلال بالینی شکست بخورند. برای بررسی این مشکل، ما دو مجموعه داده جدید پرسش و پاسخ (QA) را که از بررسیهای سیستماتیک به دست آمدهاند، معرفی مینماییم: MedRevQA (16501 جفت QA که دانش زیست پزشکی عمومی را پوشش میدهند) و MedChangeQA (زیرمجموعهای از 512 جفت QA که در آن اجماع پزشکی در طول زمان تغییر نموده است). ارزیابی ما از هشت LLM برجسته در مجموعه دادهها، اتکای مداوم به دانش منسوخ در همه مدلها را نشان میدهد. ما علاوه بر این، تأثیر دادههای منسوخشدهی پیشآموزش و استراتژیهای آموزشی را برای توضیح این پدیده تجزیه و تحلیل مینماییم و مسیرهای آینده برای کاهش آن را پیشنهاد میدهیم و زمینه را برای توسعهی سیستمهای هوش مصنوعی پزشکی بهروزتر و قابل اعتمادتر فراهم میآوریم.
۱. مقدمه
ظهور مدلهای زبان های برنامه نویسی بزرگ از پیش آموزشدیده (LLM) تحولی در حوزه پردازش زبان طبیعی (NLP) ایجاد نموده است (نوید و همکاران، ۲۰۲۵). یکی از امیدوارکنندهترین حوزههای کاربردی آنها، مراقبتهای بهداشتی است، جایی که آنها پتانسیل دموکراتیزه نمودن دسترسی به خدمات بهداشتی و کمک به گردشهای کاری بالینی حیاتی را دارند (تیروناووکاراسو و همکاران، ۲۰۲۳؛ آیرز و همکاران، ۲۰۲۳؛ لیو و همکاران، ۲۰۲۵). LLMها برای پیشبینی توکن بعدی روی حجم عظیمی از دادههای متنی آموزش دیدهاند، که منجر به رمزگذاری عمیق دانش زیادی در وزنهای آنها میشود (دینگرا و همکاران، ۲۰۲۲؛ چانگ و همکاران، ۲۰۲۴). مطالعات اخیر نشان میدهد که LLMها با آموزش دیدن روی متون پزشکی مانند سوابق بیمار و دستورالعملهای بالینی، دانش بالینی را به طور مؤثر کدگذاری مینمایند (Singhal et al., 2023; Zhang et al., 2025). توانایی مدل برای یادآوری حقایق خاص از این دادهها اغلب به عنوان حفظ نمودن شناخته میشود (Carlini et al., 2022). دانش جهانی به سرعت در حوزههای پویا مانند سرگرمی یا سیاست تکامل مییابد. با این حال، این اتفاق در مورد دانش علمی نیز رخ میدهد. در پزشکی، شواهد جدید با کیفیت بالا به طور پیوسته، پدیدار میشوند و توصیههای قبلی را منسوخ مینمایند (Hodder et al., 2024). در نتیجه، دانشی که یک LLM در زمان آموزش خود به خاطر میسپارد، میتواند قدیمی شود، زیرا آنها برای همگام شدن با دانش در حال تحول جهان تلاش دارند(Zhang et al., 2023). این یک نگرانی عمده در مورد ایمنی است، زیرا میتواند منجر به ارائه توصیههای نادرست بهداشتی توسط LLMها به مصرفکنندگان شود (لی و همکاران، 2023؛ اونگ و همکاران، 2024) یا در محیطهای بالینی هنگام استفاده از حقایق ناقص در استدلال خود شکست بخورند (هاگر و همکاران، 2024). حتی زمانی که LLMها با اطلاعات بهروز بازیابی شده تکمیل میشوند، میتوانند آن را رد نموده و در اصطلاح به تضاد دانش به دانش داخلی متوسل شوند (ژو و همکاران، 2024). در حالی که کارهای اخیر به حفظ دانش قدیمی در حوزه دانشنامهای پرداختهاند (وو و همکاران، 2024؛ چنگهائوژو و همکاران، 2025)، زوال زمانی دانش پزشکی کمتر مورد بررسی قرار گرفته است. برای پرداختن به این شکاف حیاتی، ما مجموعه دادههای جدیدی ایجاد مینماییم و از آنها برای ارزیابی به خاطر سپردن دانش پزشکی منسوخ استفاده می نماییم :
• ما MedRevQA، یک مجموعه داده جدید از ۱۶۵۰۱ جفت QA از بررسیهای سیستماتیک پزشکی را معرفی مینماییم؛ و MedChangeQA، زیرمجموعهای از ۵۱۲ جفت که در آنها پاسخها، در طول زمان تغییر نمودهاند.
• ما هشت LLM را در مجموعه دادههای خود محک میزنیم، که نشان میدهد همه مدلها اطلاعات پزشکی منسوخ شده را به خاطر میسپارند.
• ما تجزیه و تحلیل عمیقی، از جمله ردیابی دانش منسوخ شده به دادههای آموزشی، ارائه میدهیم و در مورد استراتژیهای کاهش امیدوارکننده بحث می نماییم.
مجموعه دادهها و کد در دسترس عموم هستند.
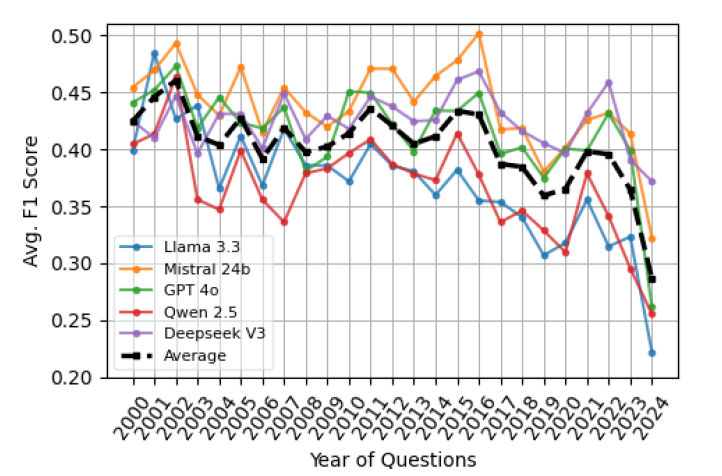
نمودار ۱: میانگین نمرات F1 پنج LLM در سوالات پزشکی که از سالهای مختلف در مجموعه دادههای ما مورد بررسی قرار میگیرند.
کاهش عملکرد با جدیدتر شدن پرسش ها، به حفظ قویتر دانش قدیمیتر اشاره دارد.
https://arxiv.org/abs/2509.04304